
本篇博文由Codex生成
如果刚开始接触智能体,一个很常见的问题是:概念都能听懂,但落到代码时还是不知道“智能体到底是怎么跑起来的”。这篇文章就用一个极小的本地项目 travel_agent_demo 来回答这个问题,并把它和 Datawhale《Hello Agents》第一章 1.3 小节“动手体验:5 分钟实现第一个智能体”对应起来。
这个项目很适合入门了解,因为它没有依赖复杂框架,而是把智能体最核心的三件事直接摊开:
- 大模型负责理解任务和决定下一步动作
- Python 函数负责充当外部工具
- 一个循环负责执行
Thought -> Action -> Observation
本地使用的环境是:
Python 3.11.3Ollamagemma4:31btavily_key
参考资料:
一、先看整体:这个智能体的结构与调用流程
Datawhale 1.3 小节的目标很明确:先写一个最小可运行 Agent,再通过它理解 Thought-Action-Observation 范式。当前这个 travel_agent_demo 项目正好就是这一思路的本地版实现。
项目结构只有 4 个核心文件:
config.py:定义系统提示词和模型配置tools.py:定义工具函数llm_client.py:封装 OpenAI 兼容接口agent.py:驱动整个行动循环
它的调用流程可以概括成下面这张图:
用户输入需求
|
v
agent.py 收集上下文并组装 Prompt
|
v
llm_client.py 调用本地 Ollama / gemma4:31b
|
v
模型输出 Thought + Action
|
+---- 如果 Action 是工具调用 ----> tools.py 执行函数
| |
| v
| 返回 Observation
|
v
agent.py 把 Observation 追加回上下文
|
v
模型继续下一轮推理
|
v
输出 Finish[最终答案]
如果换成更工程化的说法,这个项目实际上由三层组成:
- 协议层:用提示词规定模型必须输出
Thought和Action - 执行层:Python 代码解析
Action并调用工具 - 反馈层:把工具结果作为
Observation继续喂给模型
这正是 Datawhale 1.3 里最想让初学者建立起来的认知:智能体不是“会聊天的大模型”,而是“能在循环里做决策并调用工具的大模型程序”。
二、环境准备
1. Python 和依赖
项目依赖很少,requirements.txt 里只有 4 个包:
openai
requests
tavily-python
python-dotenv
安装方式:
python -m pip install -r requirements.txt
这里每个依赖的作用都很明确:
openai:访问 OpenAI 兼容接口,这里用来对接 Ollamarequests:请求天气接口wttr.intavily-python:做网页搜索python-dotenv:从.env自动加载环境变量
2. 本地模型环境
你本地已经准备好了 ollama 和 gemma4:31b,所以 LLM 侧不需要再展开安装过程。这个项目只要求 Ollama 提供 OpenAI 兼容接口即可。
推荐先确认模型已经就绪:
ollama list
如果 gemma4:31b 已经存在,就可以直接继续下面的配置。
3. 配置 .env
项目启动时会在 config.py中自动执行 load_dotenv(),因此只需要在项目根目录准备 .env 文件即可。
建议配置如下:
LLM_API_KEY=ollama
LLM_BASE_URL=http://127.0.0.1:11434/v1
LLM_MODEL=gemma4:31b
TAVILY_API_KEY=你的_tavily_key
这里有两个细节值得写进博客:
LLM_API_KEY对本地 Ollama 通常只是占位符,填ollama即可- 项目默认值里
LLM_BASE_URL是http://192.168.1.201:11434/v1,如果是本机运行,更推荐改成http://127.0.0.1:11434/v1
4. 环境准备的现实限制
这个项目并不是所有功能都只靠本地模型:
get_weather()通过wttr.in查天气,需要能访问外网web_search()和get_attraction()依赖 Tavily,需要TAVILY_API_KEY
也就是说:
- 只测模型输出格式,不一定需要 Tavily
- 想完整复现“天气 -> 景点推荐 -> 最终回答”的链路,最好配置 Tavily
三、对照 Datawhale 1.3:这个项目的每个代码块在做什么
Datawhale 1.3 大致分成三步:
- 定义系统提示词
- 定义工具
- 执行行动循环
本项目几乎就是这个结构的直接映射。
1. config.py:对应 1.3 的“定义 Agent 提示词”
config.py 里的 AGENT_SYSTEM_PROMPT 是整个智能体的协议中心。
它做了四件关键事情:
- 明确角色:你是一个“智能旅行助手”
- 明确工具:告诉模型有哪些函数可调用
- 明确格式:每次只能输出一组
Thought和Action - 明确结束条件:信息足够时必须输出
Finish[...]
对应代码位置:
- 角色与任务定义:
config.py:14 - 工具清单:
config.py:16 - 输出格式约束:
config.py:26 - 结束条件与错误处理要求:
config.py:35
这一块和 Datawhale 1.3 的核心思想完全一致。智能体之所以“可执行”,不是因为模型自己知道该怎么做,而是因为我们先定义了一个稳定的动作协议。
2. tools.py:对应 1.3 的“定义工具函数”
tools.py是这个项目和外部世界交互的地方。对智能体来说,工具就是“能力边界的延伸”。
get_weather(city: str)
入口在 tools.py:13。
它的作用是:
- 访问
https://wttr.in/{city}?format=j1 - 读取返回 JSON
- 提取天气描述和温度
- 组装成模型容易理解的字符串
这一段可以理解为 Datawhale 1.3 里“天气查询工具”的本地可运行版。
web_search(query: str)
入口在 tools.py:31。
它的作用是:
- 通过
_get_tavily_client()获取 Tavily 客户端 - 调用 Tavily 搜索网页
- 把返回的摘要、标题、链接和内容截断后整理成文本
- 作为
Observation返回给模型
为什么这里要手动整理结果,而不是把 Tavily 原始 JSON 直接塞回模型?原因很简单:原始结果太长、噪声太多,而智能体更需要“可读的摘要”。这也是 Prompt 工程和工具工程结合的典型做法。
get_attraction(city: str, weather: str)
入口在 tools.py:76。
这个函数很巧妙,它本身不直接做景点推荐,而是:
- 根据
城市 + 天气组装查询词 - 复用
web_search()去搜索“适合当前天气的旅游景点推荐及理由”
这和 Datawhale 1.3 中“根据天气再推荐景点”的第二步完全一致,只是这里把“景点推荐工具”实现成了“带业务语义的搜索封装”。
AVAILABLE_TOOLS
tools.py:82 把全部工具注册成字典:
AVAILABLE_TOOLS = {
"get_weather": get_weather,
"get_attraction": get_attraction,
"web_search": web_search,
}
这一步的意义是把“模型输出的动作字符串”映射成“程序里真实可执行的函数”。没有这层映射,模型就只是说了一个动作名字,程序并不知道该调用谁。
3. llm_client.py:对应 1.3 的“定义 LLM 客户端”
llm_client.py:4 只有一个很小的封装类 OpenAICompatibleClient,但它的作用非常关键:把本地 Ollama 包装成一个统一的“模型调用接口”。
核心逻辑有三步:
- 初始化时记录
model、api_key、base_url - 调用
chat.completions.create() - 传入
system prompt和当前轮次的user prompt
对应代码位置:
- 初始化客户端:
llm_client.py:7 - 发起模型请求:
llm_client.py:11 - 超时控制
timeout=60:llm_client.py:20
这部分和 Datawhale 1.3 的思路也一致:不要把模型调用散落在业务代码里,而是先包成一个可复用组件,后面主循环只负责“何时调模型”,不用关心底层细节。
4. agent.py:对应 1.3 的“执行行动循环”
真正体现 Agent 味道的地方在 agent.py:26
这一段建议在博客里重点展开,因为它就是 Datawhale 1.3 里最核心的执行闭环。
第一步:初始化模型和上下文
在 agent.py:27 到 agent.py:34 中,程序做了两件事:
- 创建
OpenAICompatibleClient - 初始化
prompt_history = [f"用户请求: {user_prompt}"]
这一步的作用是把“用户目标”变成第一轮推理的上下文。
第二步:进入多轮循环
agent.py:36 开始进入 for i in range(max_turns)。
这是典型的 Agent 调度器做法:
- 每一轮都让模型思考一次
- 每一轮最多执行一个动作
- 直到任务完成或达到最大轮数
这也对应 Datawhale 1.3 里反复强调的循环思路,而不是“一次提问,一次回答”的普通聊天模式。
第三步:构造本轮 Prompt
在 agent.py:38,程序通过:
full_prompt = "\n".join(prompt_history)
把历史上的用户请求、模型动作、工具观察结果全部拼起来,形成当前轮次完整上下文。
为什么要这么做?因为模型不会自动记得上一轮工具执行了什么。你必须显式把历史传回去,它才能基于新观察继续规划下一步。
第四步:调用模型生成 Thought + Action
agent.py:39 调用:
llm_output = llm.generate(full_prompt, system_prompt=AGENT_SYSTEM_PROMPT)
这正是 Datawhale 1.3 里的“让模型先思考,再给出行动”。
紧接着 agent.py:41 到 agent.py:47又做了一层截断处理,目的是防止模型一次性吐出多组 Thought/Action。这属于很实用的工程兜底,说明这个项目已经开始考虑真实模型输出的不稳定性,而不是只停留在理想示例。
第五步:解析 Action
agent.py:52到 agent.py:67先判断当前输出里是否存在 Action:,然后继续区分两类情况:
- 如果是
Finish[...],说明任务完成,直接返回最终答案 - 如果不是
Finish[...],就继续解析工具名和参数
其中工具名和参数的提取逻辑被单独封装在 agent.py:8 的 parse_action() 里。这个函数用正则把:
get_weather(city="北京")
解析成:
- 工具名
get_weather - 参数字典
{"city": "北京"}
这一步就是把“语言动作”翻译成“程序动作”。
第六步:执行工具
agent.py:69 到 agent.py:78 负责真正调用工具:
- 先通过
parse_action()解析动作 - 再到
AVAILABLE_TOOLS里查找对应函数 - 最后执行函数并拿到结果
这一段是整个 Agent 最关键的分界线:从这里开始,模型不再只是“生成文本”,而是真的触发了外部能力。
第七步:把工具结果回填为 Observation
agent.py:80 到 agent.py:83会把工具结果包装成:
Observation: ...
然后重新放回 prompt_history。
这一步就是 Thought-Action-Observation 闭环中最不能缺的一环。没有 Observation,模型就不知道刚才的行动产生了什么结果,也就无法进行下一轮更合理的决策。
第八步:控制上下文长度
和 Datawhale 1.3 的教学示例相比,这个项目多做了一点更贴近真实场景的优化:agent.py:19 定义了 summarize_observation(),在 agent.py:83 处对过长的观察结果进行截断。
这背后的原因很实际:
- 工具返回内容可能很长
- 上下文越长,本地模型越慢
- 多轮对话里如果不控制上下文,很容易拖垮响应速度
对于本地 gemma4:31b 这种大模型来说,这个小优化是有价值的。
四、把这个项目映射回 Datawhale 1.3,可以怎么理解
如果只保留最关键的对应关系,可以总结成下面这张表:
| Datawhale 1.3 的概念 | 本项目中的实现 |
|---|---|
| 系统提示词 | config.py 中的 AGENT_SYSTEM_PROMPT |
| 天气 / 景点工具 | tools.py 中的 get_weather()、get_attraction() |
| 模型客户端 | llm_client.py 中的 OpenAICompatibleClient |
| 行动循环 | agent.py 中的 run_agent() |
Thought-Action-Observation |
prompt_history + 工具调用 + Observation 回填 |
| 结束条件 | Action: Finish[...] |
所以这篇博客其实可以给读者一个很直接的结论:
Datawhale 1.3 不是一个“抽象案例”,而是一个可以直接投影到真实项目结构里的最小 Agent 模型。
五、怎么启动这个项目
启动步骤很短
1. 安装依赖
python -m pip install -r requirements.txt
2. 准备 .env
LLM_API_KEY=ollama
LLM_BASE_URL=http://127.0.0.1:11434/v1
LLM_MODEL=gemma4:31b
TAVILY_API_KEY=你的_tavily_key
3. 确认 Ollama 正在提供服务
如果你本地已经正常运行 Ollama,这一步一般不需要额外操作。只要 LLM_BASE_URL 对应的接口可访问即可。
4. 运行 Agent
python agent.py
运行后终端会提示:
请输入你的需求:
这时可以输入例如:
帮我看一下贵阳的天气,并推荐一下热门的商圈
5. 终端里会发生什么
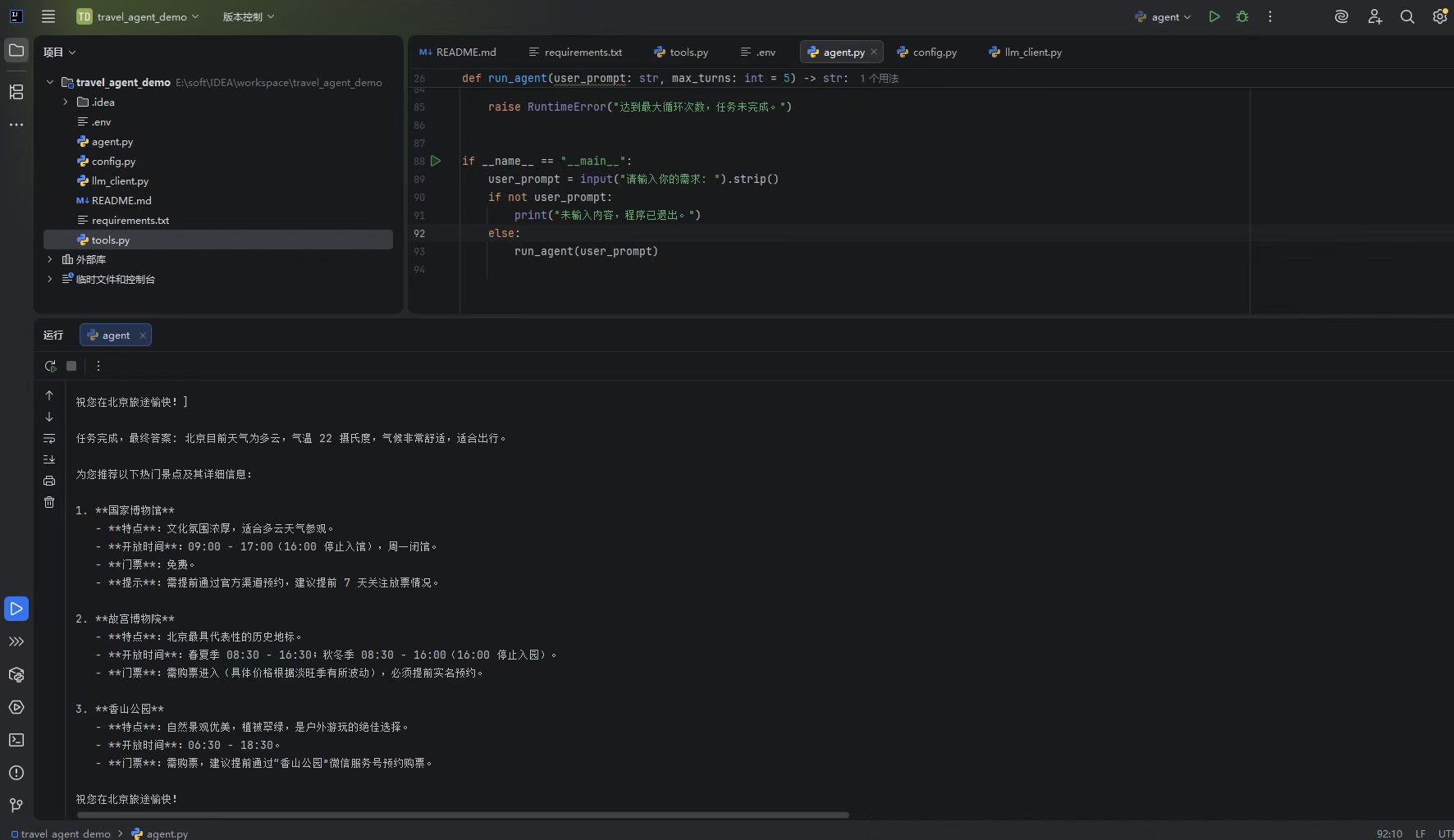
执行时你通常会看到类似下面的过程:
- 模型先输出
Thought和Action - 如果
Action是get_weather(...),程序就去查天气 - 天气结果以
Observation的形式回填 - 模型再决定是否调用
get_attraction(...)或web_search(...) - 信息足够后,模型输出
Finish[...]
这就是一个标准的最小智能体启动过程。
六、写在最后:为什么说它是“第一个智能体”,而不只是一个脚本
很多初学者第一次写这类程序时,会觉得它不过是“模型 + 函数调用”。但从 Agent 视角看,它已经具备了最基本的自主决策结构:
- 它会先判断下一步做什么
- 它会根据当前任务选择工具
- 它会利用工具结果更新自己的后续决策
- 它会在信息足够时主动结束任务
这就是智能体的最小闭环。
当然,这个项目还不是一个完整产品,它还缺少很多更高级的能力,比如长期记忆、重试机制、结构化函数调用、预算约束和更复杂的旅行规划。但作为“第一个智能体”的博客案例,它已经足够合理,甚至比直接上框架更适合入门。
如果要用一句话总结这个项目,我会写成:
travel_agent_demo的价值不在于功能多复杂,而在于它把 Datawhale 1.3 中“提示词 + 工具 + 行动循环”的智能体最小结构,用本地 Ollama 和gemma4:31b真实跑通了。